
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 유니코드 제거
- 색상변경
- 애니메이션
- 마우스클릭
- 파이썬
- 언제또가보지
- 멜버른
- 청청구역
- 가고싶은데
- 빅데이터분석기사
- 정말
- OpenGL
- 호주
- 오류
- 사각형변형
- 예쁜곳
- 방향변경
- 빅데이터분석기사필기
- 크롤링
- 갈자신이없다
- 데이터전처리
- 보라카이
- 너무오래됐다
- BeautifulSoup
- 빅데이터분석기사후기
- 필기후기
- selenium
Archives
- Today
- Total
wisdiom 아니고 wisdom
3. 데이터프레임 응용(5) 본문
5️⃣ 그룹 연산
그룹 연산이란 복잡한 데이터에 특정 기준을 적용하여 몇 개의 그룹으로 분할하여 처리하는 것을 말한다.
특히, 그룹 연산은 데이터를 집계, 변환, 필터링하는데 효율적이다.
- ☝ 분할(split) : 데이터를 특정 조건에 의해 분할
- ✌ 적용(apply) : 데이터를 집계, 변환, 필터링하는데 필요한 메소드 적용
- 👌 결합(combine) : 2단계의 처리 결과를 하나로 결합
📢 그룹 객체 만들기 (분할 단계)
📍 pandas.DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, observed=False, dropna=True)
(참고) https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.groupby.html?highlight=groupby#pandas.DataFrame.groupby
👉 1개 열을 기준으로 그룹화
#class 열을 기준으로 분할
class_group = df.groupby(['class'])
class_group.mea()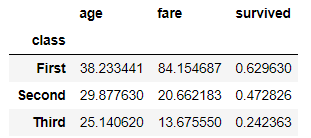
👉 여러 열을 기준으로 그룹화
# class 열, sex 열을 기준으로 그룹화
class_sex = df.groupby(['class', 'sex'])
for key, group in class_sex:
print('* key :', key)
print('* number :', len(group))
print(group.head())
print('\n')

📢 특정 그룹 선택하기
📍 group객체.get_group(name)
class_group.get_group('Third').head()
# 그룹객체에서 개별 그룹 선택하기
class_sex.get_group(('Third', 'male')).head()
📢 그룹 연산 메소드 ( 적용 - 결합 단계 )
📌 데이터 집계(aggregation)
- 📒 집계 기능을 내장하고 있는 판다스 기본 함수
- mean(), max(), min(), sum(), count(), size(), var(), std(), describe(), info(), first(), last() ...
- 📝 사용자 정의 함수를 그룹 객체에 적용하는 메소드
- 📍 group객체.agg(func)
- '모든' 열에 '여러 함수' 매핑 : group객체.agg( ['func1', func2', 'func3', ...] )
- '각' 열마다 '다른 함수' 매핑 : group객체.agg( { '열1' : '함수1' , '열2' : '함수2', ... } )
- 📍 group객체.agg(func)
👉 각 그룹에 대해 각 열의 표준편차 계산하기
class_group.std()
👉 열을 지정하여 집계 연산 적용하기
class_group['fare'].std()
🤜 집계 연산을 처리하는 사용자 정의 함수 적용하기
def min_max(x):
return x.max() - x.min()
class_group.agg(min_max)
🤜 여러 함수를 각 열(모든 열)에 동일하게 적용하기
class.group.agg(['min', 'max'])
🤜 각 열마다 다른 함수 적용하기
class_group.agg({'fare':'std', 'age':['min','max']})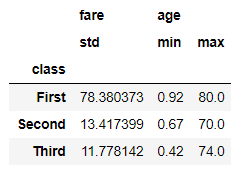
📌 그룹 연산 데이터 변환
📍 group객체.transform(func)
transform() 메소드는 그룹별로 구분하여 각 원소에 함수를 적용하나 그룹별 집계 대신 각 원소의 본래 행 인덱스와 열 이름을 기준으로 연산 결과를 반환한다. 즉, 그룹 연산의 결과를 원본 데이터프레임과 같은 형태로 변환하여 정리한다.
👉 한 열에 적용하기
# z-score 계산 함수
def z_score(x):
return (x - x.mean()) / x.std()
# 한 열에 적용
class_group.age.transform(z_score)
👉 모든 데이터에 적용하기
class_group.transform(z_score)
💡🚨 결론 🔥🔥
agg 메소드는 각 그룹별 데이터에 연산을 위한 함수를 구분해 적용하고, 그룹별로 연산 결과를 집계하여 반환한다.
transform() 메소드는 그룹별로 연산을 위한 함수를 적용하기 하지만, 그룹별로 집계하지 않고 원래 데이터프레임의 형태로 반환한다.
📌 그룹 객체 필터링
📍 group객체.filter(조건식 함수)
그룹 객체에 filter() 메소드를 적용할 때, 조건식을 가진 함수를 전달하면 참인 그룹만을 남긴다.
# age 열의 평균이 30보다 작은 그룹만을 필터링
class_group.filter(lambda x: x.age.mean() < 30)
📌 그룹 객체에 함수 매핑
📍 group객체.apply(func)
apply() 메소드는 판다스 객체의 개별 원소를 특정 함수에 일대일로 매핑한다.
사용자가 원하는 대부분의 연산을 그룹 객체에도 적용할 수 있다.
👉 기존 집계 함수 적용하기
# 집계 : 각 그룹별 요약 통계 정보 집계
class_group.apply(lambda x: x.describe())
👉 사용자가 정의한 집계 함수 적용하기
# 사용자 정의 함수
class_group.age.apply(z_score)
👉 필터링 적용하기
# 필터링 : age 열의 데이터 평군이 30보다 작은 그룹만을 선택
class_group.apply(lambda x: x.age.mean() < 30)
for x in age_filter.index:
if age_filter[x] == True:
age_filter_df = class_group.get_group(x)
print(age_filter_df.head(), '\n')
반응형
'👩💻 > pandas' 카테고리의 다른 글
| 4. 머신러닝 데이터 분석(0) (0) | 2021.02.04 |
|---|---|
| 3. 데이터프레임 응용(6) (0) | 2021.02.02 |
| 3. 데이터프레임 응용(4) (0) | 2021.01.31 |
| 3. 데이터프레임 응용(0) (0) | 2021.01.31 |
| 3. 데이터프레임 응용(3) (0) | 2021.01.31 |
'👩💻/pandas' Related Articles
more




Comments